AutoGPT:当 AI 学会自主思考(核心能力分析)

ChatGPT 的出现让我们看到了 AI 对话的强大能力,但你有没有想过:如果 AI 不仅能回答问题,还能自主规划、执行任务,会是什么样子?
这就是 AutoGPT 正在做的事情——让 AI 从”被动回答”进化到”主动行动”。
从对话到自主
使用 ChatGPT 时,我们通常是这样的循环:
用户提问 → ChatGPT 回答 → 用户评估 → 继续提问 → ...
这个过程需要人类不断参与评估和反馈。那么,能不能让这个过程自动化?
AutoGPT 的答案是:自主运行的 GPT,无需或少需人工干预。
它的核心思想很简单:给定一个目标,AI 自己决定下一步做什么,执行后评估结果,再决定下一步行动,直到目标完成。
AutoGPT 的五大核心
1. 任务定义
一切从定义开始。用户需要提供:
- Name:AI 代理的名字(如 “WebScraper-GPT”)
- Role:角色定位(如 “专门从事网页抓取和数据提取的自主代理”)
- Goals:最多 5 个目标(如 “爬取网站新闻标题并保存到文件”)
2. 思考(Thinking)
AI 收到任务后,会先进行”思考”。这模仿了人类的决策过程——接到任务先想清楚要做什么。
3. 规划(PLAN)
思考之后,AI 会生成一个 Step-by-Step 的执行计划。比如:
- 浏览目标网站获取 HTML
- 编写解析脚本提取标题
- 将结果保存到文件
4. 决策(CRITICISM)
从多个步骤中选择优先执行的一个,并生成具体的执行指令。例如:
{
"command": "browse_website",
"args": {
"url": "https://example.com",
"question": "extract news titles"
}
}
5. 执行与评估
执行指令后,AI 会评估结果是否达到预期,决定是继续下一步还是调整策略。
工作流程:循环的力量
AutoGPT 的核心是一个不断循环的执行流程:
定义任务 → 理解任务 → 生成方案 → 生成指令 → 执行指令 → 输出结果 → 评估结果 → 循环
这个循环会一直持续,直到所有目标完成。这就是”自主”的本质——AI 自己决定下一步做的事情。
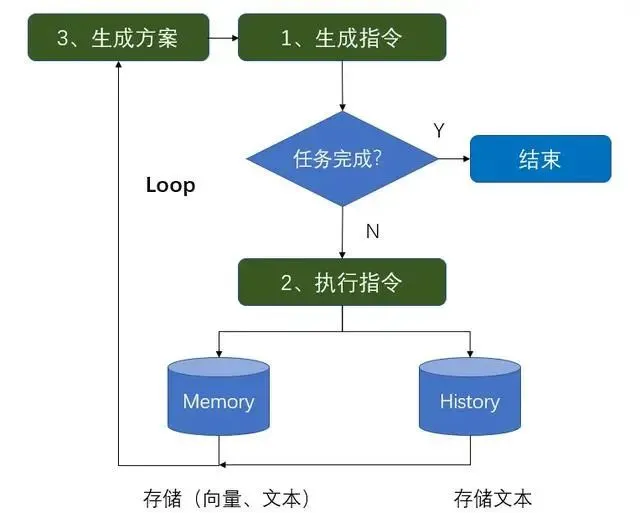
记忆系统:短期与长期
AutoGPT 有两种记忆机制:
短期记忆(History)
存储最近的对话历史,受限于 Token 数量(如 GPT-3.5 的 4096)。就像人类的短期记忆,只保留最近发生的事情。
长期记忆(Memory)
存储关键信息,以向量形式存入数据库。当需要时,通过相似度检索找到相关记忆。
为什么这样设计?
- 短期记忆保证上下文的连贯性
- 长期记忆确保重要信息不丢失
这种组合让 AutoGPT 既能保持对话的连贯,又能从历史经验中学习。
命令系统:AI 的”手”和”脚”
AutoGPT 通过命令系统与外部世界交互。它内置了 20 多个命令,包括:
信息获取:
google:谷歌搜索browse_website:浏览网站
文件操作:
write_to_file:写入文件read_file:读取文件append_to_file:追加文件
代码执行:
execute_python_file:执行 Python 脚本evaluate_code:评估代码improve_code:优化代码
代理管理:
start_agent:启动子代理message_agent:向子代理发送消息
其他:
generate_image:生成图片send_tweet:发送推特
这些命令就像是 AI 的”手”和”脚”,让它能够真正做事情,而不只是说说而已。
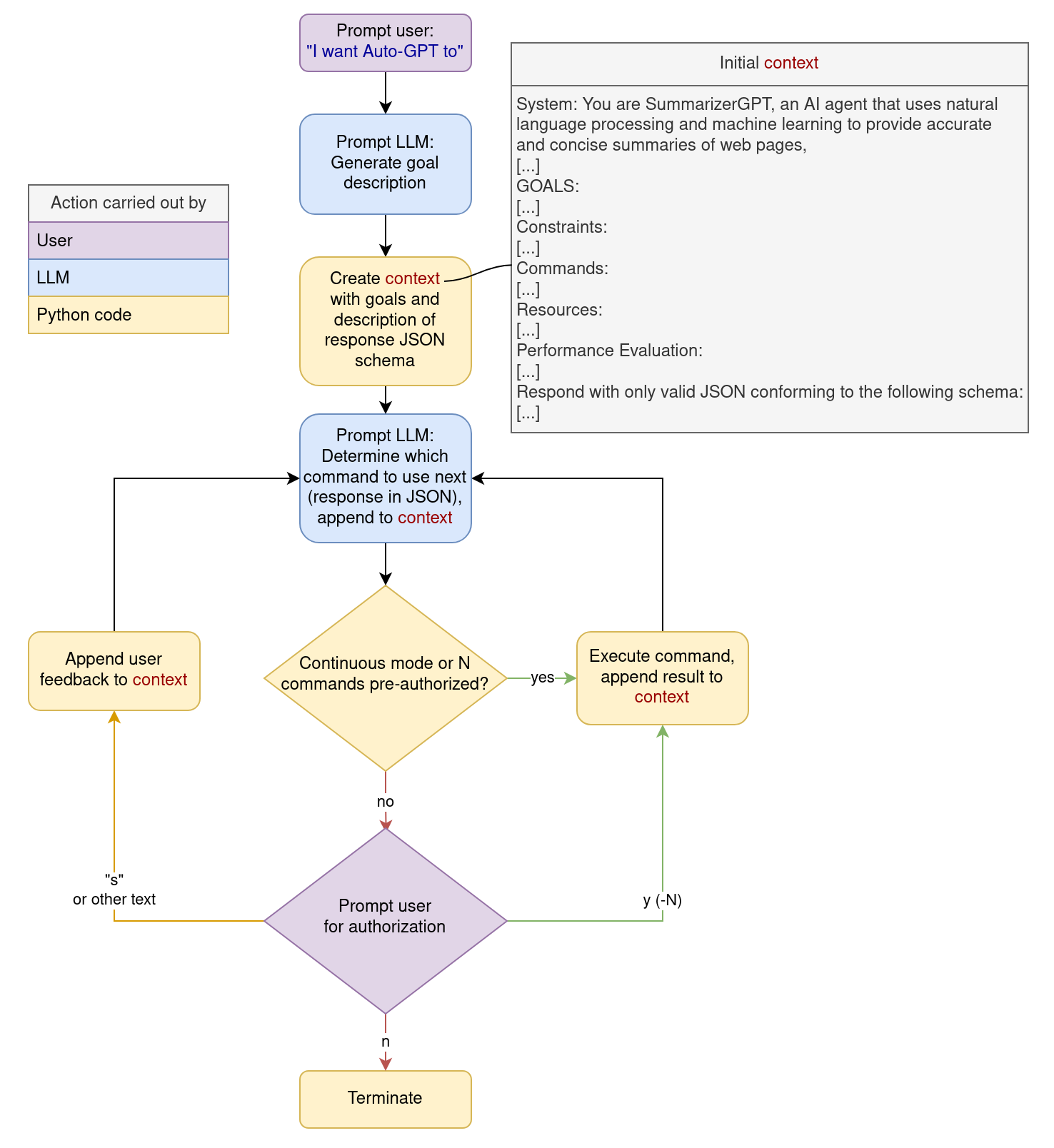
实际应用案例
案例:自动爬取新闻标题
假设我们想让 AutoGPT 爬取某个网站的新闻标题:
定义任务:
Name: NewsScraper-GPT
Role: 专门从事网页抓取的自主代理
Goals:
1. 导航到网站并提取新闻标题
2. 将标题保存为 result.txt
3. 持续监控网站更新
执行过程:
- AutoGPT 思考后决定先浏览网站
- 执行
browse_website命令获取页面内容 - 解析 HTML 提取标题
- 执行
write_to_file保存结果 - 评估是否完成所有目标
- 循环继续或结束
整个过程完全自动化,无需人工干预。
其他应用场景
市场调研智能体
- 分析竞争对手
- 生成优缺点报告
- 收集用户反馈
社交媒体管理
- 监控多个社交账号
- 分析内容互动数据
- 生成运营报表
内容创作
- 自动撰写文章
- 生成配图
- 发布到多个平台
技术原理拆解
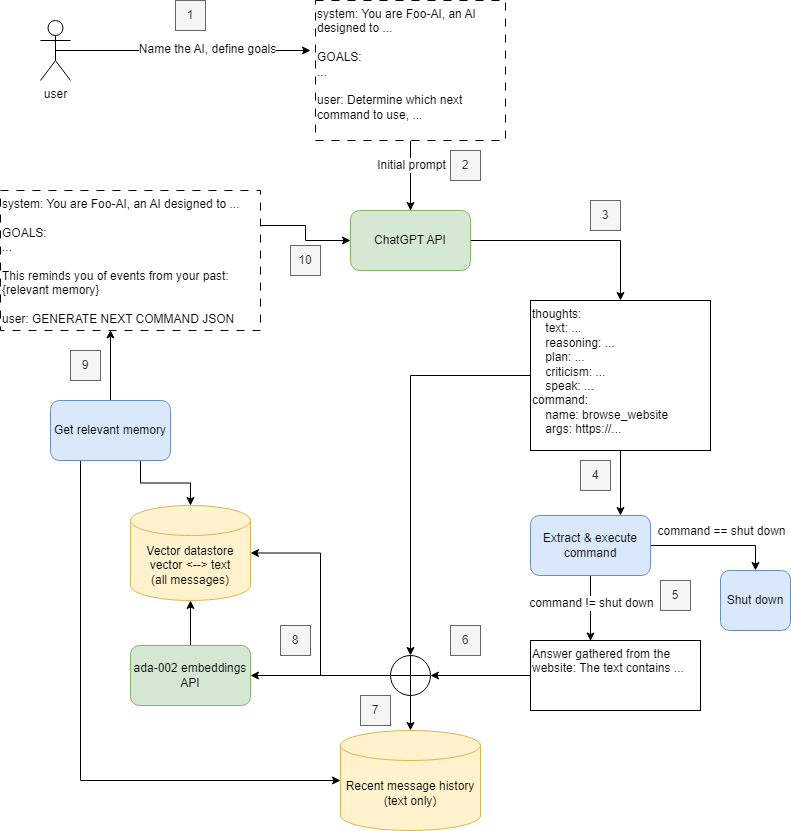
如何理解任务?
AutoGPT 的理解能力来自:
- 预训练知识:ChatGPT 在训练过程中学习了各种角色、目标和上下文的关联
- Zero-shot Learning:即使面对从未见过的任务,也能通过语义相似性进行推理
如何分解任务?
采用 Multi-Task Learning(MTL) 思想:
- 将单个任务拆解为多个子任务
- 共享特征表示层学习通用特征
- 每个子任务有特定的输出层
例如”爬取新闻并保存”会被拆解为:
- 浏览网站获取 HTML
- 解析 HTML 提取标题
- 保存到文件
如何生成新方案?
结合两种记忆:
- 长期记忆:存储角色、目标、关键信息
- 短期记忆:最近的对话历史
每次生成新 Prompt 时,会:
- 选择最近的 N 条历史记录
- 检索相关度最高的 M 条长期记忆
- 组合作为输入
这样既保证了上下文连贯,又利用了历史经验。
面临的挑战
尽管 AutoGPT 展现了惊人的能力,但也面临诸多挑战:
1. 缺乏真正的推理能力
AutoGPT 的核心是通过 Prompt Engineering 实现的,但它没有显性引入 Chain of Thought(CoT)。这意味着它没有真正解锁大模型的推理能力。
为什么会这样?研究表明,只有在引入 CoT 后,超过 1000 亿参数的大模型才能解锁 reasoning 能力。AutoGPT 虽然要求输出包含 “reasoning” 和 “planning”,但这只是格式要求,并非真正的推理过程。
这导致 AutoGPT “有勇无谋”——它能不断尝试执行命令,但缺乏真正的思考,只能依赖缓存和经验做决策。
2. 成本问题
每次循环都需要调用 ChatGPT API,复杂任务可能需要几十甚至上百次调用。在没有真正推理能力的情况下,大量重复的尝试让成本更加高昂。
3. 稳定性
AI 的决策过程具有随机性,同样的任务可能产生不同的执行路径,结果不一定稳定。
4. Token 限制
上下文长度有限,长任务可能导致早期信息丢失。
5. 错误累积
一次错误的决策可能导致后续步骤都偏离目标。
6. 安全性
自主执行命令带来了潜在的安全风险,需要严格的权限控制。
未来的方向
AutoGPT 只是开始。要理解它的未来,我们需要先看看大语言模型使用工具的发展历程:
LLM 工具使用的发展
阶段一:Reinforcement Learning
在 CoT 和 ReAct 出现之前,LLM 学会调用 API 主要依赖昂贵的 Human Feedback Reinforcement Learning。例如 WebGPT 通过人工反馈让模型学会调用 Bing Search API。
阶段二:ReAct
ReAct 将 Chain of Thought 动态引入到 LLM 学习调用 API 的过程中。它让 LLM 在做决策前先进行推理,用 Thought → Action → Observation 的循环,轻量级地解决了模型学习工具的问题。
阶段三:多模态扩展
MM-ReAct 等方法进一步拓展了边界,让 LLM 能够协调视觉专家模型,完成多模态复杂任务。
AutoGPT 的定位
在这个发展脉络中,AutoGPT 处在一个有趣的位置:
- 它没有 Reinforcement Learning 的加持
- 也没有显性的 CoT 或 ReAct 模式
- 本质上还是 Prompt Engineering
就像一个“动力十足但思维跟不上”的实习生——有行动力,但缺乏真正的推理能力。
真正的突破方向
引入 Chain of Thought
CoT 本质也是 Prompting,但它如此轻成本。如果 AutoGPT 能够显性引入 CoT 或 ReAct 模式,在执行每个命令前先进行推理,将会变得更加强大:
Thought: 我需要获取网站上的新闻标题
Reasoning: 首先应该浏览网站获取 HTML,然后解析提取标题
Action: browse_website
Observation: 获取到页面内容
Thought: 页面已获取,现在需要解析 HTML...
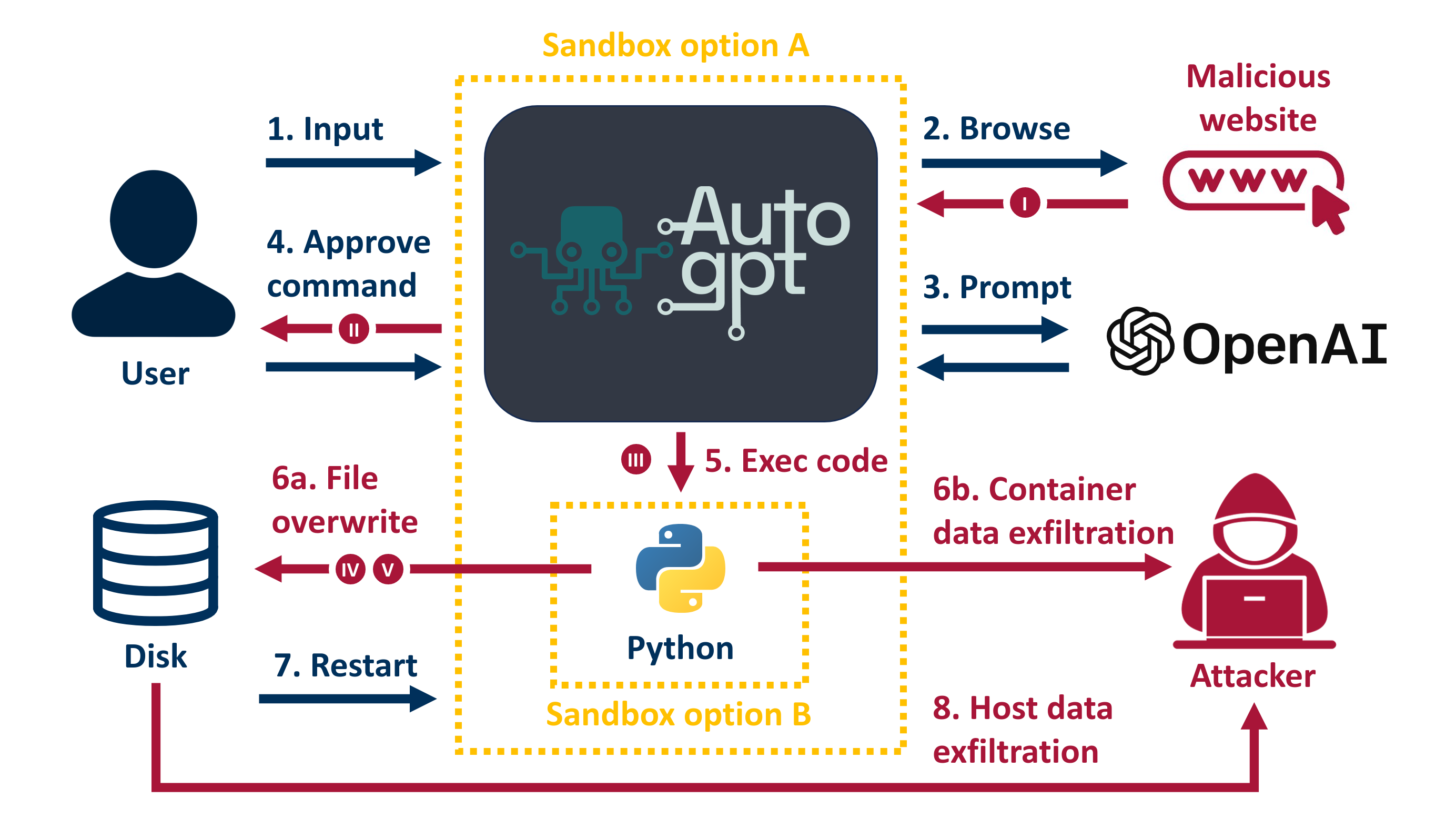
其他改进方向:
- 更好的记忆机制
- 分层记忆系统
- 自动记忆整理
- 跨会话记忆持久化
- 更强的规划能力
- 长期规划
- 动态调整计划
- 多任务协调
- 更丰富的工具集
- API 集成
- 物理设备控制
- 专业工具调用
- 人机协作
- 关键节点人工确认
- 异常情况人工介入
- 学习人类偏好
思考:AI 的进化
从 ChatGPT 到 AutoGPT,再到引入 CoT/ReAct 的未来版本,我们看到 AI 的进化路径:
被动回答 → 主动规划 → 自主执行 → 真正推理 → 持续学习
这个进化路径很有意思:
- ChatGPT:AI 作为工具,人类主导
- AutoGPT:AI 作为代理,能行动但缺乏深度思考
- AutoGPT + CoT/ReAct:AI 具备推理能力,思考后行动
- 未来:AI 作为伙伴,人机协作
AutoGPT 的出现让我们看到了 AI 自主执行的可能性,但它的局限性也提醒我们:真正的智能不仅需要行动力,更需要思考力。
当行动力与思考力结合,AI 将从”实习生”进化为真正的”助手”。
一个有趣的观察
随着模型越来越大,我们看到的趋势是:
- Fine-tuning 和 Human Feedback RL 变得越来越昂贵
- Zero-shot / Few-shot 成为潮流
- CoT 解锁了模型涌现的推理能力
- ReAct 将推理能力拓展到工具使用
在这个背景下,AutoGPT 的方向是对的——通过 Prompting 而非 Fine-tuning 来实现功能。但它还需要引入 CoT/ReAct 的思想,才能真正释放大模型的潜力。
结语
AutoGPT 展示了一种可能性:AI 不只是被动的问答机器,还可以是主动的问题解决者。
它像一个”动力十足但思维跟不上”的实习生,有行动力但缺乏推理深度。但这个方向是对的——通过 Prompting 而非昂贵的 Fine-tuning 来实现功能。
如果 AutoGPT 能够引入 Chain of Thought 或 ReAct 模式,让 AI 在行动前先进行真正的推理,它将变得远比现在强大。
从 ChatGPT 到 AutoGPT,从对话式 AI 到代理式 AI,我们正在见证一场深刻的变革。而真正的突破,或许出现在行动力与思考力完美结合的那一刻。
当 AI 学会自主思考,我们的工作方式将被重新定义。
注:本文基于 AutoGPT v0.2.1 的架构分析及社区讨论,截至 2023 年 6 月,AutoGPT 已发布至 v0.2.2,相关技术正在快速发展中。感谢 @realrenmin 等研究者的深入分析。