DeepAgent vs DeepResearch:两种深度智能体架构范式的对照分析

当 AI Agent 从”调用工具的脚本”进化到能够自主决策的系统时,一个关键的问题浮现出来:你的 Agent 应该有多大的自主权?
这个问题将 Agent 设计划分为了两种不同的路径:
- DeepAgent:完全自主的工具发现者和决策者
- DeepResearch Agent:结构化的研究者,遵循预定义的研究流程
这不仅仅是技术实现的差异,更是两种不同的 AI 哲学。让我们深入探讨。
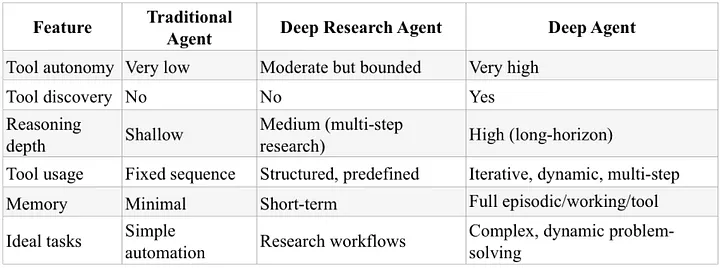
从传统到深度:理解 Agent 的进化
在深入对比之前,我们需要先厘清一个更基础的分类。根据论文《DeepAgent: A General Reasoning Agent with Scalable Toolsets》,Agent 的发展可以分为三个阶段:
传统 Agent 工作流
用户提问 → 选择工具 → 执行 → 返回结果
特征:
- 预定义的步骤序列
- 有限的自主权:开发者决定用哪个工具、何时用、用多少次
- 工具是固定的、预先已知的
- 记忆和长期推理能力通常很弱
这就像一个老式的自动化脚本,能完成任务,但缺乏灵活性。
DeepAgent:完全自主的智能体
DeepAgent 代表了下一代 Agent 的特征:完全自主。
目标 → 动态规划 → 工具发现 → 执行 → 评估 → 迭代 → 完成
核心特征:
- 自主工具选择:它自己决定用哪个工具、何时使用、使用多少次
- 工具发现能力:可以从大量工具中选择合适的,而不是局限于预定义列表
- 长期记忆管理:通过 episodic memory、working memory、tool memory 管理交互历史
- 推理与执行紧密集成:不是简单的”LLM 输出工具调用”的流水线
伪代码示例:
# DeepAgent - 动态决策和工具发现
agent = create_deep_agent(
llm=llm,
tools=[
fetch_billing,
analyze_usage,
inspect_logs,
recommend_actions,
report_writer
]
)
# Agent 在运行时自主决定调用顺序
result = agent.run("帮我降低公司的云成本")
# 执行轨迹示例(动态生成):
# PLAN -> fetch_billing()
# EVAL -> 发现异常 -> inspect_logs()
# EVAL -> 发现空闲实例 -> recommend_actions()
# FINAL -> report_writer()
DeepResearch Agent:结构化的研究者
DeepResearch Agent 是 Agent 的一个变体,专注于结构化的多步骤研究任务。
问题 → 收集 → 分析 → 综合 → 报告
核心特征:
- 固定工具集:工具是预先已知的(web search、PDF reader、code executor等)
- 结构化流程:遵循预定义的研究管道
- 可重复性:工具调用顺序是预指定的,不会自发调用未知工具
- 证据驱动:强调可验证的分析和清晰的证据链
伪代码示例:
# DeepResearch Agent - 固定的研究管道
research_agent = create_deep_research_agent(
llm=llm,
pipeline=[
gather_stage(
fetch_billing,
fetch_inventory,
pricing_lookup
),
analyze_stage(
statistical_analysis,
anomaly_detection
),
synthesize_stage(
cost_models,
prioritization
),
report_stage(report_writer)
],
max_depth=3
)
# 运行固定的管道
report = research_agent.run("帮我降低公司的云成本")
# 输出:带有证据、置信度评分、详细建议的报告
关键差异:自主性 vs 可控性
让我们用一个具体的场景来对比两种 Agent 的行为差异。
场景:降低公司云成本
DeepAgent 的行为模式
想象一个初级云工程师被赋予了完全访问权限(在限制范围内),被告知”降低成本”。
执行流程:
1. PLAN: 制定初步策略(获取账单摘要)
2. EVAL: 调用账单 API → 查看结果
3. ADAPT: 发现异常 → 决定获取日志
4. EVAL: 调用日志分析工具(运行时动态决定的新工具调用)
5. RE-PLAN: 重新规划 → 提出优化方案(预留实例、修改自动扩展)
6. ACTION: 生成行动项 + 简短报告
关键特点:
- 基于中间输出动态选择工具
- 灵活但难以预测和治理
- 可以处理未预见的情况
DeepResearch Agent 的行为模式
想象一位高级分析师被聘用来制作可复现的审计报告。
执行流程:
阶段 1 - GATHER(收集)
├── 获取 90 天账单数据
├── 编制实例清单
└── 查询定价信息
阶段 2 - ANALYZE(分析)
├── 比较使用量 vs 预算
├── 检测空闲/低利用率实例
└── 识别异常模式
阶段 3 - CROSS-CHECK(交叉验证)
├── 对比定价选项(预留、储蓄计划、Spot 实例)
└── 评估折扣计划
阶段 4 - REPORT(报告)
└── 生成带证据、置信度评分、逐步建议的详细报告
关键特点:
- 工具调用顺序预先指定
- 可复现、可解释的结果
- 更容易的安全控制
本质差异总结
| 维度 | DeepAgent | DeepResearch Agent |
|---|---|---|
| 决策风格 | 动态决策 | 固定流程 |
| 工具使用 | 运行时发现和选择 | 预定义集合 |
| 可预测性 | 难以预测 | 高度可预测 |
| 风险特征 | 高自主性带来治理风险 | 可控、可审计 |
| 适用场景 | 自动化、修复、运维 | 审计、合规、深度研究 |
| 输出特点 | 行动 + 简短报告 | 详细证据链 + 分析报告 |
决策风格的影响
为什么这种差异很重要?
1. 可复现性
- DeepResearch Agent 每次运行相同的输入会产生相同的步骤
- DeepAgent 可能根据中间结果采取不同的路径
2. 安全与治理
- DeepAgent 的自主性带来新的风险:
- 数据暴露
- 意外操作
- 不可预测的工具调用
- DeepResearch Agent 更容易实现:
- 沙箱隔离
- 人工审批
- 审计追踪
3. 责任归属
- DeepAgent:决策由 AI 做出,责任模糊
- DeepResearch Agent:流程清晰,责任明确
如何选择:Framework vs 直接使用模型 API
在构建 Agent 之前,还有一个关键的技术决策需要做出。
使用模型 API(ChatGPT、Claude、Gemini 等)
适用场景:
- 工作流简单或线性
- 清楚知道要调用哪个工具/函数
- 只需要 1-3 步推理
- 更像”智能函数调用”而非自主 Agent
- 希望完全控制内存、状态、循环和工具调用
- 追求最大效率和最小延迟
优势:
- 更低的延迟
- 完全的可见性和控制
- 更高的效率
- 更简单的基础设施
使用 Agentic 框架(LangGraph、CrewAI、OpenAI Agents SDK)
适用场景:
- 需要分支逻辑、决策或复杂工作流
- 需要长期运行的任务或自我管理的多步骤过程
- 工具需要被编排,而不仅仅是调用一次
- 需要内置的结构化状态、共享内存和行为控制
- 需要可观测性、重试、护栏或多 Agent 协调
- 计划未来进化到更深层或更自主的 Agent 行为
优势:
- 自动处理循环、状态、内存、工具路由和工作流管理
- 适合复杂系统
- 内置的可观测性和调试工具
权衡:便利性 vs 控制
| 维度 | 模型 API | Agentic 框架 |
|---|---|---|
| 控制力 | 完全控制 | 框架管理 |
| 开发效率 | 需要更多工程工作 | 快速启动 |
| 性能 | 更低延迟 | 可能更慢 |
| 可见性 | 每步都可见 | 框架封装 |
| 复杂度 | 简单任务更简单 | 复杂任务更简单 |
生产环境的风险与治理
DeepAgent 的治理挑战
完全自主的 Agent 带来新的安全和治理风险:
1. 数据安全风险
- Agent 可能访问不该访问的数据
- 工具链组合可能暴露敏感信息
- 难以预测的数据流路径
缓解措施:
- 严格的沙箱隔离
- 工具权限细粒度控制
- 审计日志和监控
- 人工审批关键操作
2. 操作风险
- 意外的系统修改
- 级联错误
- 资源过度消耗
缓解措施:
- 操作预览和确认机制
- 资源限制和超时
- 回滚能力
- 多层验证
DeepResearch Agent 的治理优势
结构化流程天然带来更好的可控性:
优势:
- 可审计的执行路径
- 可复现的结果
- 清晰的审批点
- 易于测试和验证
适用场景:
- 金融合规审计
- 医疗数据研究
- 法律文档分析
- 任何需要严格审计追踪的场景
实用决策指南
选择 DeepAgent 当:
✅ 你需要系统自主行动(自动化、修复、运维) ✅ 任务需要动态工具组合 ✅ 场景难以预见,需要 Agent 自己决策 ✅ 可以接受一定的不确定性,追求灵活性
⚠️ 记住做好治理:
- 严格的沙箱隔离
- 完善的监控和日志
- 人工审批关键操作
选择 DeepResearch Agent 当:
✅ 你需要可复现的分析(审计、合规、深度研究) ✅ 强调证据链和可解释性 ✅ 需要清晰的审计追踪 ✅ 希望结果稳定可控
✅ 天然优势:
- 更容易测试和验证
- 更容易获得利益相关者信任
- 更容易满足合规要求
一个混合策略
很多成功的产品实际上采用了混合架构:
class HybridAgent:
def solve(self, problem):
# 阶段 1: 结构化研究(可控)
research = self.research_module.analyze(problem)
# 阶段 2: 人工审批关键决策
if self.needs_approval(research):
research = self.wait_for_approval(research)
# 阶段 3: 自主执行(高效)
if self.can_auto_execute(research):
result = self.agent_module.execute(research.plan)
else:
result = self.human_execute(research.action_items)
return result
这种模式在保持可控性的同时,也获得了自主性带来的效率提升。
结语
DeepAgent 和 DeepResearch Agent 的划分,本质上是在回答一个根本性的问题:
我们希望 AI 有多大的自主权?
这不是一个技术问题,而是一个信任和治理的问题。
关键要点回顾
DeepAgent:
- 完全自主,动态工具发现
- 灵活、强大,但难以预测
- 适合自动化、运维、修复场景
- 需要严格的治理和监控
DeepResearch Agent:
- 结构化流程,固定工具集
- 可复现、可解释、可审计
- 适合研究、审计、合规场景
- 天然更安全可控
Framework vs API:
- 简单任务 → 直接使用模型 API
- 复杂工作流 → 使用 Agentic 框架
真正的洞察
最成功的产品往往不是极端的选择,而是明智的混合:
- 用 DeepResearch Agent 做可控的研究和规划
- 用人工审批关键决策
- 用 DeepAgent 执行明确的操作
这种混合模式在保持可控性的同时,也获得了 AI 带来的效率提升。
本文基于《DeepAgent: A General Reasoning Agent with Scalable Toolsets》论文以及 Sindhuja A 的博客文章 “How to Build AI Agents That Work” 的分析总结。