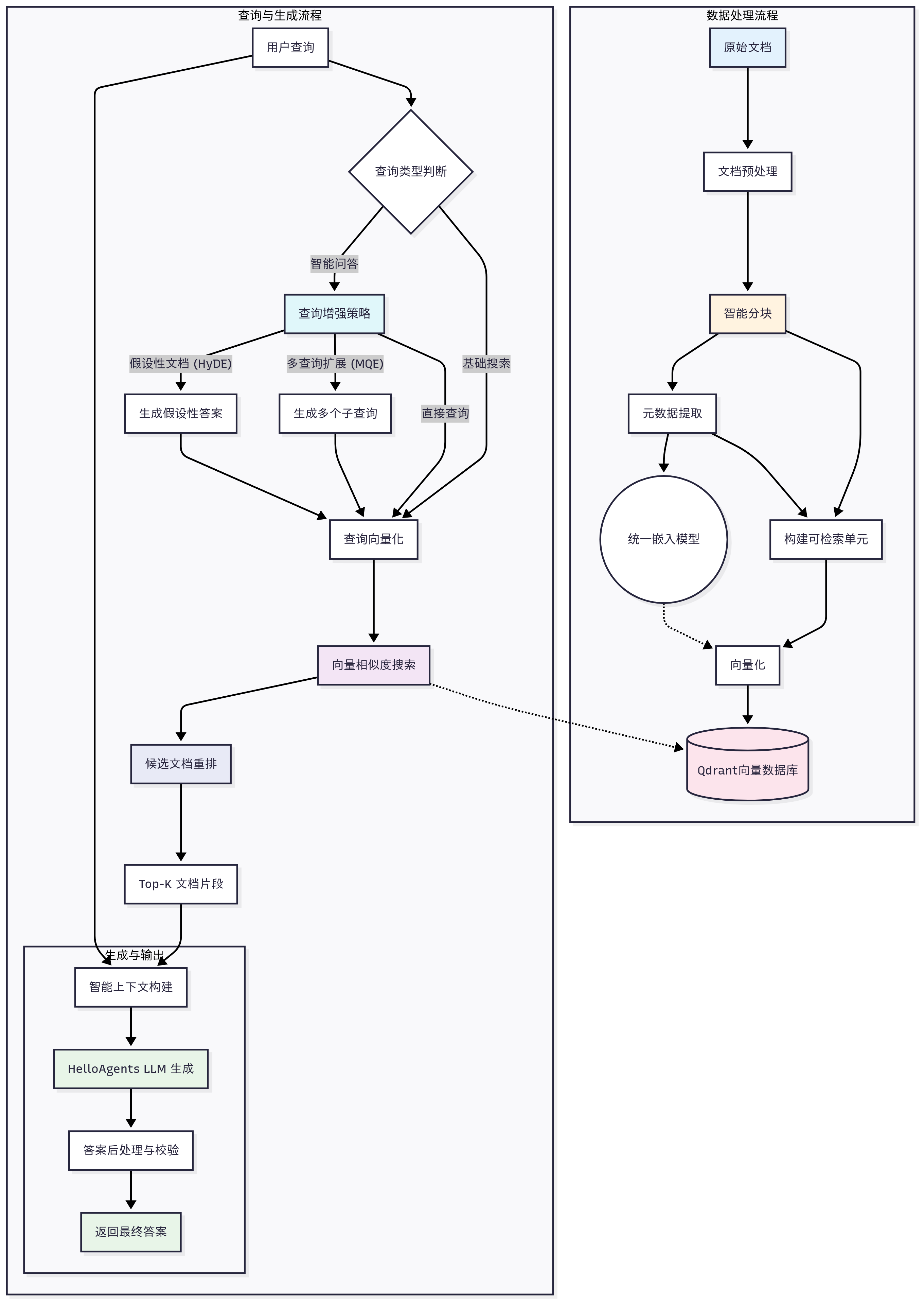
模块化RAG技术路线图:从Naive到Advanced再到Modular
2024年,RAG(Retrieval-Augmented Generation,检索增强生成)技术已经成为AI应用的核心架构之一。从最初的Naive RAG到Advanced RAG,再到如今的Modular RAG,这条技术路线图清晰地展示了RAG技术的演进路径。
一、为什么需要RAG?
直接使用大语言模型存在诸多局限:
| 直接使用LLM的缺陷 | 实际应用的需求 |
|---|---|
| 幻觉问题 | 领域精准问答 |
| 信息过时 | 数据频繁更新 |
| 参数化知识效率低 | 生成内容可解释可溯源 |
| 缺乏专业领域深度知识 | 成本可控 |
| 推理能力弱 | 数据隐私保护 |
RAG的核心思想是:让LLM在回答问题时,先从大量文档中检索相关信息,然后基于这些信息生成回答。
用户查询 → 检索相关文档 → 生成回答
↑
知识库
这种架构使得我们不必为每个特定任务重新训练整个大模型,只需外挂知识库即可。RAG特别适合知识密集型任务,具有以下优势:
- 解决知识更新问题
- 减少幻觉
- 具有良好的可解释性
- 成本可控
二、Naive RAG:基础架构
Naive RAG是最简单的RAG实现,包含三个核心组件:检索、增强、生成。
2.1 检索技术
关键词检索
传统的关键词检索通过倒排索引实现:
- 对文档进行分词
- 使用BDK Tree等数据结构建立倒排索引
- 通过TF-IDF/BM25等算法计算相关性
BM25是广泛使用的排名函数:
BM25得分 = Σ IDF(qi) × (f(qi, D) × (k1 + 1)) /
(f(qi, D) + k1 × (1 - b + b × |D| / avgdl))
其中:
f(qi, D): 词项qi在文档D中的频率IDF(qi): 词项qi的逆文档频率k1, b: 调节参数
向量检索
向量检索通过深度学习模型将文本转换为向量,然后计算向量相似度:
| 特性 | 关键词检索 | 向量检索 |
|---|---|---|
| 索引速度 | 快 | 慢 |
| 查询速度(大数据) | 快 | 较慢 |
| 精确匹配精度 | 完美 | 较低 |
| 语义搜索精度 | 无法捕获 | 较高 |
向量索引类型:
- Linear索引:暴力检索,召回率最高,但性能差
- QC(量化聚类):倒排聚类,内存效率高,召回率有损失
- HNSW:分层小世界图,性能与召回率平衡
- 全量QC + 增量HNSW:结合两者优势
主流向量模型:
- CohereAI(商业最强)
- BGE(开源最强)
- BGE-M3:多语言、多粒度、多功能一体化
混合检索
结合稀疏检索(关键词)和稠密检索(向量)的优势:
# 伪代码
def hybrid_search(query):
# 稀疏检索
sparse_results = bm25_search(query)
# 稠密检索
dense_results = vector_search(query)
# 结果融合
return fusion(sparse_results, dense_results)
2.2 分段策略
为什么要分段?
- 长度限制:模型有输入长度限制
- 提升检索效率:更小的向量维度和计算开销
- 提高检索质量:更精确地定位相关部分
分段方法:
- 固定长度分段:简单但可能切断语义
- 语义分段:基于句子边界和语义完整性
- 滑动窗口:保证每段语义完整且有重叠
- 小到大(Small-to-Big):先检索小段落,再扩展到上下文
2.3 生成阶段
使用大语言模型基于检索到的上下文生成答案。标准Prompt结构:
指令:你是一个专业的问答助手
上下文:[检索到的相关文档]
输入:{用户问题}
输出:根据上下文回答问题
三、Advanced RAG:高级优化
根据OpenAI的分享,只有基础的检索+生成准确率只能达到45%。Advanced RAG在检索前、中、后三个阶段进行优化。
3.1 检索前优化(Pre-Retrieval)
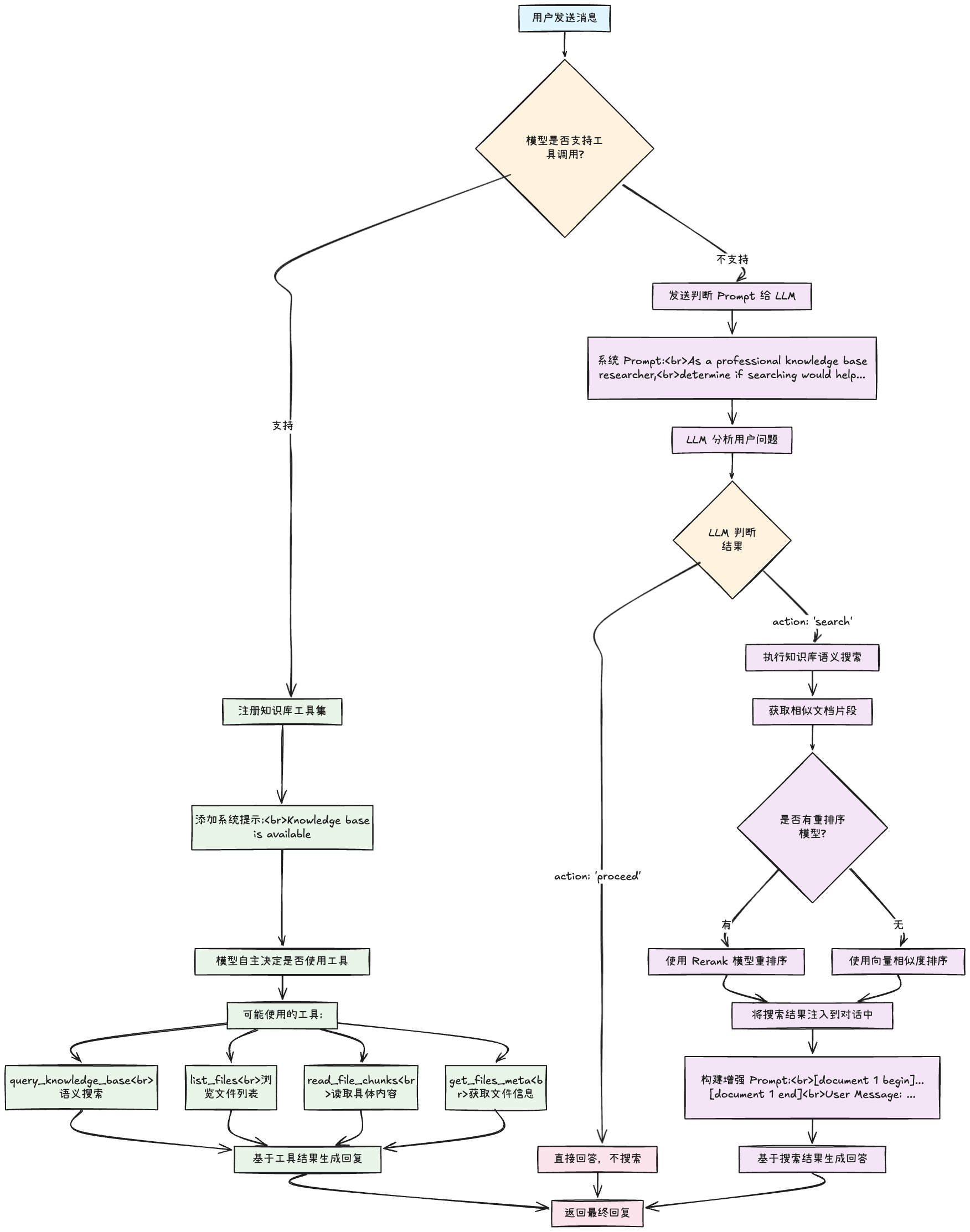
查询路由(Query Routing)
根据查询类型决定:
- 使用什么引擎(文档库 vs 关系数据库 vs 知识图谱)
- 使用什么索引(向量索引 vs 摘要索引)
查询改写(Query Rewrite)✨
问题与答案不一定有高语义相似度,需要对Query进行调整:
1. 子查询分解(Sub-query)
适用于多跳问题和对比问题:
原始查询:"小张和小李的专业有什么共同点?"
改写为:
- "小张的专业是什么?"
- "小李的专业是什么?"
- "这两个专业的共同点是什么?"
2. RRR(Rewrite-Retrieve-Read)
- 改写模块将对比问题拆解
- 使用奖励模型微调改写模型
- 小参数模型实现快速改写
3. DSP(Demonstrate-Search-Predict)
将多跳问题拆解为子查询,递归检索直到得到答案。
4. 多查询(Multi-query)
对模糊问题生成多个清晰问题:
原始问题(模糊):"那个东西怎么样?"
↓
生成多个清晰问题:
- "iPhone 15 Pro怎么样?"
- "华为Mate 60 Pro怎么样?"
- "小米14 Ultra怎么样?"
↓
分别检索并汇总答案
5. 假设性生成(HyDE)
让LLM先生成假设性答案,再用答案向量检索:
查询:"什么是量子计算?"
↓
LLM生成假设答案:"量子计算是利用量子力学原理..."
↓
使用(查询 + 假设答案)进行向量检索
6. Step-Back Prompting
找到复杂问题的上层概念:
具体问题:"小美2010年在哪里上学?"
↓
抽象问题:"小美的教育经历"
记忆机制(Memory)
- 短期记忆:会话状态跟踪(DST)
- 长期记忆:
- 记忆召回
- 记忆总结
- 用户画像生成
3.2 检索中优化(Retrieval & Indexing)
分段优化
滑动窗口(Sliding Window):
文档:[段落1][段落2][段落3][段落4][段落5]
↓
分段:[1-2][2-3][3-4][4-5]
(有重叠,保证语义完整)
小到大(Small-to-Big):
先检索:小段落(精准定位)
再扩展:相邻段落合并(完整上下文)
元信息抽取
抽取文档和段落的关键信息:
- 文档级:发表时间、作者、标题
- 段落级:多级标题、相关查询、摘要
- 实体级:命名实体识别
知识图谱增强
1. KG增强文档结构
使用知识图谱表示多文档关系,提升检索精度。
2. 实体抽取与子图检索
查询:"马斯克的公司有哪些?"
↓
实体抽取:"马斯克"
↓
检索子图:马斯克 → [Tesla, SpaceX, X, ...]
↓
基于子图生成答案
3. NL2Cypher查询
将自然语言转换为Cypher查询语言,直接查询知识图谱。
3.3 检索后优化(Post-Retrieval)
重排(Reranking)
为什么需要重排?
- 检索阶段使用近似算法,精度有损失
- 向量模型有性能考虑,不能保证精确度
重排方法:
- 相关性模型:Cohere Rerank、BGE Reranker
- 混合评分:结合BM25分数、文档质量分、点击量
- 多样性重排:选择最相关且最不重复的文档
- LostInTheMiddle:优化文档顺序,避免重要信息被忽略
原始排序:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
优化排序:[1, 3, 5, 7, 9, 10, 8, 6, 4, 2]
↑
重要信息放在两头
Prompt优化
- 信息压缩:使用小模型压缩上下文,减少噪声
- 模板选择:根据场景选择合适的Prompt模板
四、Modular RAG:模块化架构
随着RAG技术的发展,需要更灵活和可组合的架构。Modular RAG将RAG抽象为可组合的模块。
4.1 模块增强(Augmented Module)
将RAG流程拆解为独立模块,每个模块可以独立优化和替换:
┌─────────────────────────────────────────┐
│ 查询理解 │ 查询改写 │ 查询路由 │
├─────────────────────────────────────────┤
│ 索引选择 │ 检索执行 │ 结果融合 │
├─────────────────────────────────────────┤
│ 重排序 │ 上下文优化 │ 答案生成 │
└─────────────────────────────────────────┘
4.2 链路增强(Augmented Process)
Modular RAG不仅关注”检索什么”,更关注”什么时候检索”。
迭代RAG(Iterative RAG)
查询 → 检索 → 生成 → 检索 → 生成 → ...
↑ ↑
使用前一轮生成结果优化查询
N次迭代或LLM判断可以回答后停止。
递归RAG(Recursive RAG)
模糊问题 → 检索 → 生成清晰问题 → 检索 → ...
↑
如果仍模糊,递归生成
例如Tree of Clarifications(TOC):
原始问题:AQ(模糊)
↓
生成多个清晰问题:DQ1, DQ2, DQ3
↓
如果DQi仍模糊 → 生成DQij
↓
形成清晰问题树
自适应RAG(Adaptive RAG)
FLARE(Forward-Looking Active Retrieval):
生成 → 遇到低置信度token → 停止
↓
生成问题 → 检索 → 继续生成
Self-RAG:
- 微调模型,让模型学会判断何时需要检索
- 生成特殊token表示需要检索
- 对生成结果进行自我评判
- 选择最优结果继续生成
查询 → LLM判断:需要检索?
↓ 是
检索 → 生成多个候选 → 评判 → 选择最优 → 继续生成
↓ 否
直接生成 → 评判 → 输出
五、RAG评估体系
5.1 检索评估
纯检索指标:
- 精准率(Precision):相关文档 / 检索到的文档
- 召回率(Recall):检索到的相关文档 / 所有相关文档(北极星指标)
- F1分数:精确率和召回率的调和平均
检索与重排指标:
- MRR(平均倒数排名):最相关文档的倒数排名平均值
- MAP(平均精确率均值):考虑所有相关文档的排序质量
- NDCG(归一化折损累计增益):位置敏感的评价指标
基于LLM的检索评估:
- Relevance:查询与文档的相关性(GPT4准确率79%)
- Context Coverage:检索到的文档能否生成标准答案
注意:LLM评估可用于对比优化方向,但准确率不足以评估真实准确率。
5.2 生成评估
生成结果评估:
- Correctness:与标准答案对比
- Relevance:答案与查询的相关性
- Logic:答案的逻辑性
- Style:生成风格(长短、语气等)
生成阶段评估:
- Faithfulness:答案是否忠于上下文
- Noise Robustness:从噪声文档中提取有用信息的能力
- Negative Rejection:检索不到时是否拒绝回答
- Info Integration:整合多文档信息的能力
- Counterfactual Robustness:识别文档中事实错误的能力
LLM在生成评估方面表现优于传统方法。
六、技术路线图总结
Naive RAG(基础)
↓
Advanced RAG(优化)
├── 检索前:查询改写、路由、记忆
├── 检索中:混合检索、分段优化、KG增强
└── 检索后:重排、Prompt优化
↓
Modular RAG(模块化)
├── 模块增强:独立可替换的组件
└── 链路增强:迭代、递归、自适应
七、实践建议
7.1 从简单开始
- 先实现Naive RAG:快速验证可行性
- 评估瓶颈:找出问题所在(检索?生成?)
- 针对性优化:根据瓶颈选择Advanced RAG技术
- 模块化重构:逐步演进到Modular RAG
7.2 技术选择
| 场景 | 推荐技术 |
|---|---|
| 通用问答 | 向量检索 + 重排 |
| 精确匹配 | 关键词检索 + 向量检索 |
| 多跳问题 | 查询改写 + 迭代RAG |
| 实时数据 | 查询路由 + 混合索引 |
| 领域知识 | KG增强 + Fine-tuning |
7.3 性能优化
- 索引优化:选择合适的索引类型(HNSW/QC)
- 缓存策略:热门查询结果缓存
- 批量处理:向量检索和重排批量化
- 模型选择:不同阶段使用不同规模的模型
结语
从Naive RAG到Advanced RAG,再到Modular RAG,这条技术路线图展示了RAG技术从简单到复杂、从单一到灵活的演进过程。
关键趋势:
- 从固定流程到灵活组合:Modular RAG让开发者像搭积木一样构建RAG系统
- 从被动检索到主动决策:自适应RAG让AI学会何时检索、检索什么
- 从单一技术到融合创新:向量检索、知识图谱、查询改写等技术深度融合
RAG技术仍在快速发展中,未来可能会看到更多创新:
- 多模态RAG(图像、视频、音频)
- 强化学习优化检索策略
- 更智能的查询理解和改写
- 更高效的长文档处理
无论如何演进,模块化和可组合性将是RAG技术发展的核心方向。
注:本文基于模块化RAG技术的最新研究整理,相关技术仍在快速发展中。